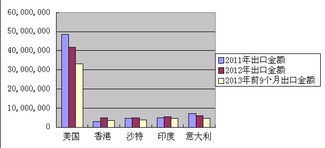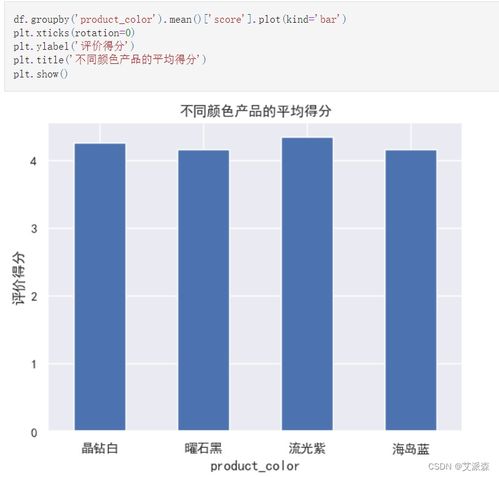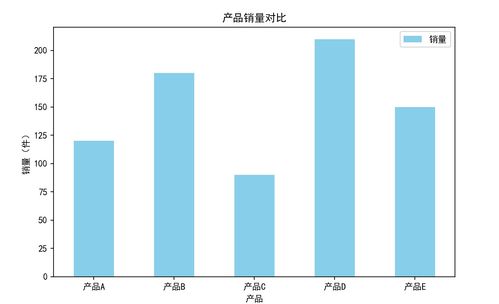
在当今数据驱动的时代,数据分析已成为决策过程中不可或缺的一环。而数据可视化,作为将复杂数据转化为直观图形的艺术,是理解数据、发现模式、传达见解的关键手段。在Python生态系统中,pandas与seaborn是两个强大且协同工作的库,它们极大地简化了从数据处理到高级可视化的整个工作流。
1. pandas:数据操作的基石
pandas是Python数据分析的核心库,它提供了快速、灵活且富有表现力的数据结构,旨在使数据清洗、转换和分析变得简单直观。其核心数据结构是DataFrame——一种二维的、大小可变的、具有潜在不同类型列的表格型数据结构。
在进行可视化之前,我们通常需要先利用pandas进行数据准备:
- 数据加载:轻松读取CSV、Excel、SQL数据库等多种来源的数据。
- 数据清洗:处理缺失值、异常值,进行数据类型转换。
- 数据转换:通过分组(groupby)、合并(merge)、透视(pivot)等操作重塑数据,使其更适合绘图。
例如,一个简单的数据加载与预览:`python
import pandas as pd
# 加载数据
df = pd.readcsv('yourdata.csv')
# 查看数据概览
print(df.info())
print(df.head())`
2. seaborn:统计图形的美学升华
seaborn是基于matplotlib构建的高级数据可视化库。它提供了一个高级接口,用于绘制具有吸引力且信息丰富的统计图形。其设计哲学是与pandas的DataFrame对象无缝集成,并且默认样式和调色板更加美观。seaborn的核心优势在于它能够用简洁的语法绘制复杂的图表,并自动处理许多统计细节。
其主要特点包括:
- 与pandas集成:直接使用DataFrame的列名作为参数。
- 丰富的图表类型:支持散点图、线图、柱状图、箱线图、小提琴图、热力图、分布图、回归图等。
- 自动统计聚合:在绘制条形图或箱线图时,可以自动计算均值、中位数、置信区间等。
- 多变量关系可视化:轻松展示多个变量之间的关系(如pairplot, relplot)。
- 美观的默认主题:无需复杂配置即可获得专业外观的图表。
3. 强强联合:数据分析与可视化工作流
典型的工作流程是:先用pandas处理和探索数据,再用seaborn进行可视化探索和展示。
示例:分析客户数据集
假设我们有一个客户数据集customers.csv,包含年龄、收入、消费分数等信息。
`python
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
设置seaborn风格
sns.set_style('whitegrid')
1. 数据准备 (pandas)
df = pd.read_csv('customers.csv')
# 检查数据
print(df.describe())
# 处理缺失值(例如用中位数填充)
df['Age'].fillna(df['Age'].median(), inplace=True)
2. 单变量分布分析 (seaborn)
查看年龄分布
plt.figure(figsize=(10,6))
sns.histplot(data=df, x='Age', kde=True, bins=30)
plt.title('Customer Age Distribution')
plt.show()
3. 双变量关系分析
年龄与收入的关系(散点图)
plt.figure(figsize=(10,6))
sns.scatterplot(data=df, x='Age', y='AnnualIncome', hue='Gender')
plt.title('Age vs. Annual Income by Gender')
plt.show()
4. 多变量与分类分析
按性别分组的收入箱线图
plt.figure(figsize=(8,6))
sns.boxplot(data=df, x='Gender', y='AnnualIncome')
plt.title('Annual Income Distribution by Gender')
plt.show()
5. 复杂关系探索:成对关系图
选取数值型列
numericcols = ['Age', 'AnnualIncome', 'SpendingScore']
sns.pairplot(df[numericcols], diag_kind='kde')
plt.suptitle('Pairwise Relationships', y=1.02)
plt.show()
6. 聚合与热力图(相关性矩阵)
corrmatrix = df[numericcols].corr()
plt.figure(figsize=(8,6))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', center=0)
plt.title('Correlation Heatmap')
plt.show()`
4. 进阶技巧与最佳实践
- 分面绘图:使用
seaborn的FacetGrid或catplot、relplot的col/row参数,可以基于某个分类变量创建多个子图,便于比较。 - 自定义与美化:虽然seaborn默认美观,但依然可以深度自定义颜色、样式、字体等,以匹配报告或出版要求。
- 性能考虑:对于超大型数据集,在绘图前考虑使用pandas进行采样或聚合,以避免图形渲染过慢。
- 解释与叙事:永远记住,可视化是为叙事服务的。为图表添加清晰的标题、轴标签,并在必要时添加注释,引导观众关注关键发现。
结论
pandas与seaborn的组合为数据分析师和科学家提供了一个从原始数据到深刻见解的“快速通道”。pandas负责将混乱的数据整理得井井有条,而seaborn则将这些数据转化为清晰、美观且富有统计意义的视觉故事。掌握这两个工具,意味着你能够更高效地探索数据、验证假设,并以令人信服的方式将分析结果呈现给他人。无论是探索性数据分析(EDA)还是最终的报告呈现,这对黄金搭档都是现代数据分析工具箱中的必备利器。